Fit Birch
Implements the BIRCH clustering algorithm. It is a memory-efficient, online-learning algorithm provided as an alternative to MiniBatchKMeans. It constructs a tree data structure with the cluster centroids being read off the leaf. These can be either the final cluster centroids or can be provided as input to another clustering algorithm such as AgglomerativeClustering.
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) is an algorithm for efficiently clustering large datasets by creating a hierarchical structure of clusters through node splitting and merging operations.
Usage:
Open the algorithm from the processing toolbox.
Load an existing training dataset or create one by clicking the processing algorithm icon, then click run.
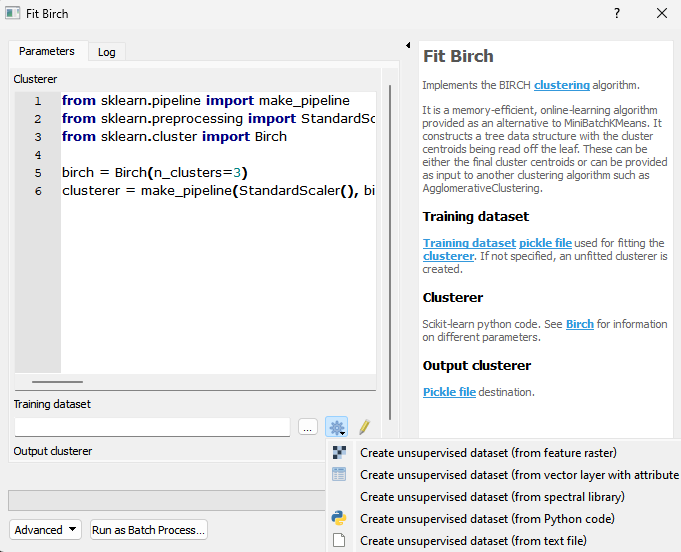
Parameters
- Clusterer [string]
Scikit-learn python code. See Birch for information on different parameters.
Default:
from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.cluster import Birch birch = Birch(n_clusters=3) clusterer = make_pipeline(StandardScaler(), birch)
- Training dataset [file]
Training dataset pickle file used for fitting the clusterer. If not specified, an unfitted clusterer is created.
Outputs
- Output clusterer [fileDestination]
Pickle file destination.
Command-line usage
>qgis_process help enmapbox:FitBirch:
----------------
Arguments
----------------
clusterer: Clusterer
Default value: from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import Birch
birch = Birch(n_clusters=3)
clusterer = make_pipeline(StandardScaler(), birch)
Argument type: string
Acceptable values:
- String value
- field:FIELD_NAME to use a data defined value taken from the FIELD_NAME field
- expression:SOME EXPRESSION to use a data defined value calculated using a custom QGIS expression
dataset: Training dataset
Argument type: file
Acceptable values:
- Path to a file
outputClusterer: Output clusterer
Argument type: fileDestination
Acceptable values:
- Path for new file
----------------
Outputs
----------------
outputClusterer: <outputFile>
Output clusterer