1. Regression-based unmixing of urban land cover
Authors: Akpona Okujeni, Patrick Hostert, Benjamin Jakimow, Andreas Janz, Fabian Thiel, & Sebastian van der Linden
Contributors: Klara Busse, Sam Cooper, Clemens Jaenicke
Publication date: 05/02/2019
Latest update: 23/01/2024
1.1. Introduction
1.1.1. 1. Background
This tutorial is featured on the HYPERedu online learning platform, an educational initiative under the EnMAP mission hosted on EO College. HYPERedu offers annotated slide collections and hands-on tutorials utilizing the open-source EnMAP-Box software, covering fundamental principles, methods, and applications of imaging spectroscopy.
Slide collections with annotations for the tutorial Regression-based unmixing of urban land cover and a software description unit for the EnMAP-Box can be found here:
In addition to this tutorial, the unit Imaging spectroscopy for urban mapping offers an introduction to the capabilities of imaging spectroscopy for urban mapping.
1.1.2. 2. Content
Land cover fraction mapping based on unmixing is well suited to describe the composition of surface types in heterogeneous environments, particularly when using coarser spatial resolution satellite data with a high share of mixed pixels. Fraction mapping proves more useful than discrete classification, as exemplified by the utilization of 30 m resolution imagery from the spaceborne imaging spectrometer mission EnMAP for urban mapping.
This tutorial focuses on regression-based unmixing of urban land cover, utilizing synthetically mixed training data from spectral libraries. The exercises incorporate hyperspectral images from both the airborne HyMap sensor and the spaceborne EnMAP mission (simulated here from HyMap), along with a corresponding spectral library and reference land cover information. The tutorial is designed to offer both a theoretical foundation addressing challenges in urban mapping and a hands-on training for effectively working the EnMAP-Box.
1.1.3. 3. Requirements
This tutorial is designed for EnMAP-Box 3, version 3.13.0 or higher. Minor changes may be present in subsequent versions, such as modified menu labels or added parameter options.
1.1.4. 4. Further Reading
We recommend [1] for a comprehensive overview on imaging spectroscopy of urban environments. We refer to [2] and [3] for conceptual introductions into the regression-based unmixing workflow using synthetically mixed training data, and [4] for a description of the latest implementation.
1.1.5. 4. Data
The tutorial data can be downloaded here: Download Data
The tutorial data covers a region along the urban gradient of Berlin, Germany. It consists of a simulated hyperspectral EnMAP image at 30 m resolution, a corresponding hyperspectral HyMap image at 3.6 m resolution, a spectral library, and detailed land cover reference information.
Data type |
Filename |
Description |
|---|---|---|
Raster |
|
Airborne hyperspectral data from the HyMap sensor with a spatial resolution of 3.6 m, 111 bands and 346x3200 pixels (GeoTIFF |
Raster |
|
Spaceborne hyperspectral data from the EnMAP sensor (here simulated from HyMAP) with a spatial resolution of 30 m, 177 bands and 220x400 pixels (GeoTIFF |
Spectral library |
|
Urban spectral library with 75 pure surface materials categorized in a hierarchical class scheme. The Library was developed from the HyMap image and spectrally resampled to the EnMAP sensor (Geopackage |
Vector |
|
Detailed land cover reference information categorized in a hierarchical class scheme (GeoPackage |
The tutorial data is a subset extracted from the Berlin-Urban-Gradient dataset [5]. Please cite the dataset as follows:
1.2. Exercise A: Urban land cover
Description
Airborne imaging spectroscopy data proves highly effective for urban mapping. The combination of high spectral and spatial resolution enhances the separability of surface types and preserves intricate spatial details of various urban features. This exercise…
Provides an insight into how urban areas are depicted by airborne hyperspectral images and introduces a hierarchical classification scheme commonly adopted for urban mapping.
Introduces basic functionalities of the EnMAP-Box. You will familiarizing yourself with the graphical user interface, and learn how to load data, visualize raster and vector data, and use the basic navigation tools.
Duration: 15 min
1.2.1. 1. Start the EnMAP-Box
Launch QGIS and click the
 icon in the toolbar to open the EnMAP-Box. The EnMAP-Box GUI comprises a Menu and a Toolbar, panels for Data Sources and Data Views, and the QGIS Processing Toolbox, which includes the EnMAP-Box geoalgorithms.
icon in the toolbar to open the EnMAP-Box. The EnMAP-Box GUI comprises a Menu and a Toolbar, panels for Data Sources and Data Views, and the QGIS Processing Toolbox, which includes the EnMAP-Box geoalgorithms.
1.2.2. 2. Load data
The EnMAP-Box provides easy drag-and-drop functionality for loading data from an external explorer. Simply drag the datasets listed below from your explorer into the Data Sources panel:
Raster:
hymap_berlin.tif,enmap_berlin.tifVector:
landcover_berlin.gpkgSpectral library:
library_berlin.gpkg
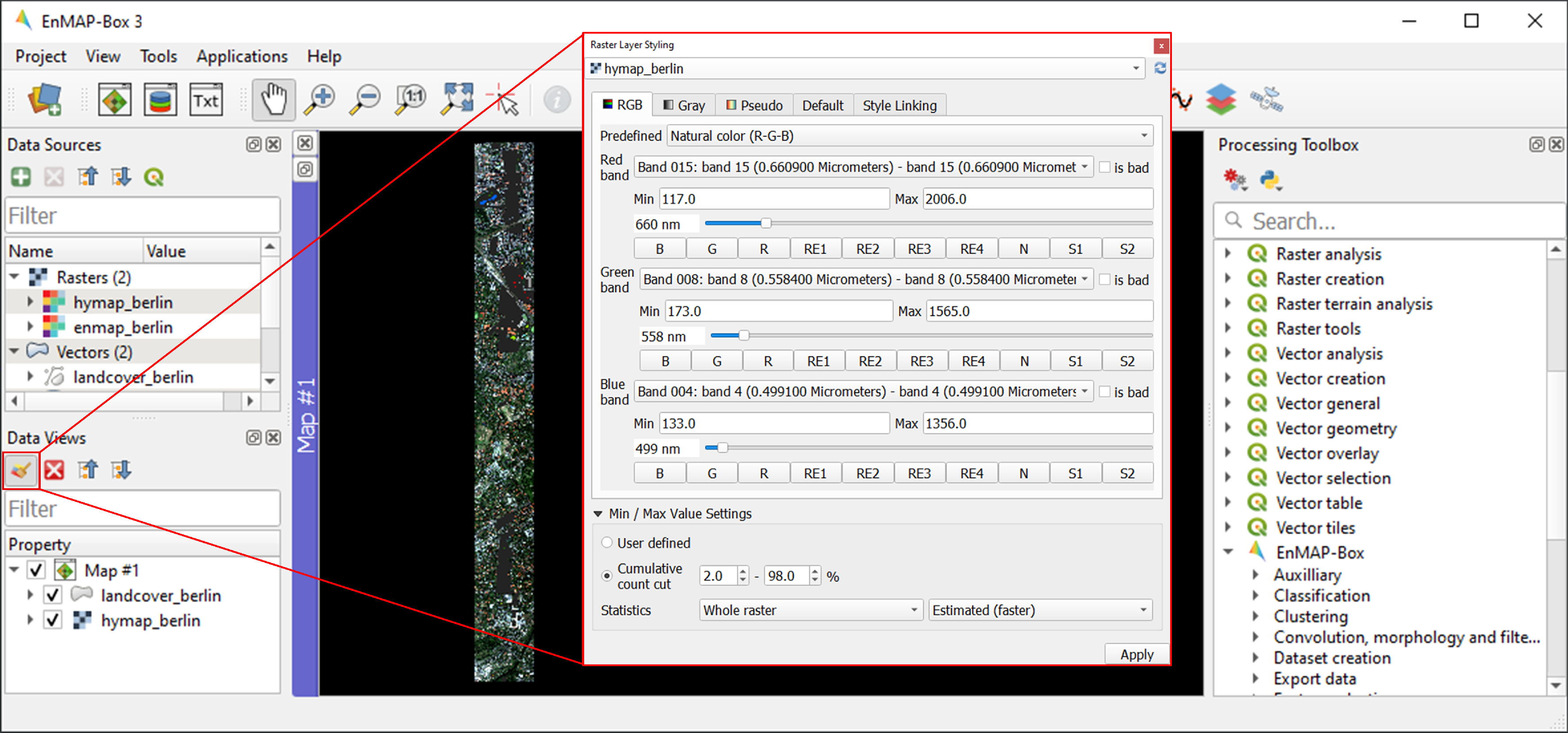
1.2.3. 3. Visualize raster and vector data
The EnMAP-Box provides Map Windows (Map #) for visualizing raster and vector data. Click the
 icon, and drag the datasets listed below from the Data Sources panel into Map #1:
icon, and drag the datasets listed below from the Data Sources panel into Map #1:hymap_berlin.tiflandcover_berlin.gpkg
Map #1 is now visible in the Data Views panel, where the visibility, order and properties of datasets can be modified. Expand Map #1. To adjust the order of stacked layers, drag one layer above or below another. Organize the layers so that
landcover_berlin.gpkgis displayed abovehymap_berlin.tif.Raster Layer Styling is a versatile tool for defining or modifying the RGB representation of raster images, either manually or through pre-defined settings.
Open the Raster Layer Styling panel by clicking the
 icon in the Data Views panel.
icon in the Data Views panel.Choose
hymap_berlin.tiffrom the dropdown menu and the RGB tab as render type.You can now choose between various pre-defined RGB representations from the dropdown menu (note: rasters needs to have wavelength information) or manually specify your RGB band combination. Choose True/Natural color R-G-B.
You may further use the functionalities offered for contrast enhancement (e.g. Cumulative count cut: 2-98%).
The symbology for
landcover_berlin.gpkgis predefined by a QGIS layer style file (.qml). You can modify the symbology using standard QGIS functionality.Right-click on the vector layer, select Layer Properties and navigate to Symbology.
Coose Categorized and use the Value and Classify options to explore the information content of the attribute table and modify the representation of the land cover information.
1.2.4. 4. Basic navigation tools
The toolbar provides standard navigation tools for exploring visualized datasets. Familiarize yourself with the following navigation tools:
 . Additionally, note that you can use the mouse wheel alternatively for zooming (roll the mouse wheel forward/backward) and panning (press and hold the mouse wheel)
. Additionally, note that you can use the mouse wheel alternatively for zooming (roll the mouse wheel forward/backward) and panning (press and hold the mouse wheel)amiliarize yourself with the crosshair functionality. To show/hide the crosshair, change its style, or display the pixel cell of a selected layer, right-click within MAP #1 and select Crosshair.
Learning activities:
A1: Visually explore the airborne hyperspectral image (
hymap_berlin.tif). What major land cover types do you observe along Berlin’s urban-gradient?click to expand...
Major land cover types: buildings/roofs, paved areas (e.g., streets, backyards), trees (e.g., park trees, street trees), grass (e.g., lawns, soccer field), crops (on agricultural sites), bare soil (e.g., agricultural sites, construction sites), and water (e.g., lakes, swimming pools).
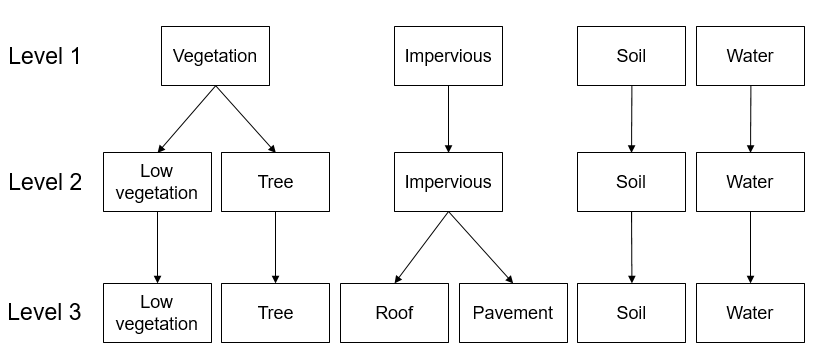
A2: Explore the land cover reference data (
landcover_berlin.gpkg) and draw a flowchart of the hierarchical classification scheme stored in the attribute table.click to expand...
1.3. Exercise B: Spectral mixing
Description
Spaceborne imaging spectroscopy missions create new opportunities for global urban mapping. However, the transition to satellite observations comes with coarser spatial resolution, leading to a loss in spatial detail and an increase in the number of mixed pixels.
Provides an insight into how urban areas are depicted by spaceborne hyperspectral images and illustrates challenges associated with spectral mixing when using such data for urban mapping.
Introduces additional basic functionalities of the EnMAP-Box. You will learn how to work with multiple map views, and how to visualize image spectra using Spectral Library Windows.
Duration: 15 min
1.3.1. 1. Multiple map views
Close Map #1 from the previous exercise by using the
 icon on the blue Map #1 title bar.
icon on the blue Map #1 title bar.The EnMAP-Box allows users to work with multiple Map Windows, which can be organized and geospatially linked. Open two new Map Windows. For horizontal arrangement, click and hold on the blue Map #2 title bar, then drag it to the right edge of of Map #1. A transparent blue rectangle will appear, indicating the docking position once you release the mouse button.
Display
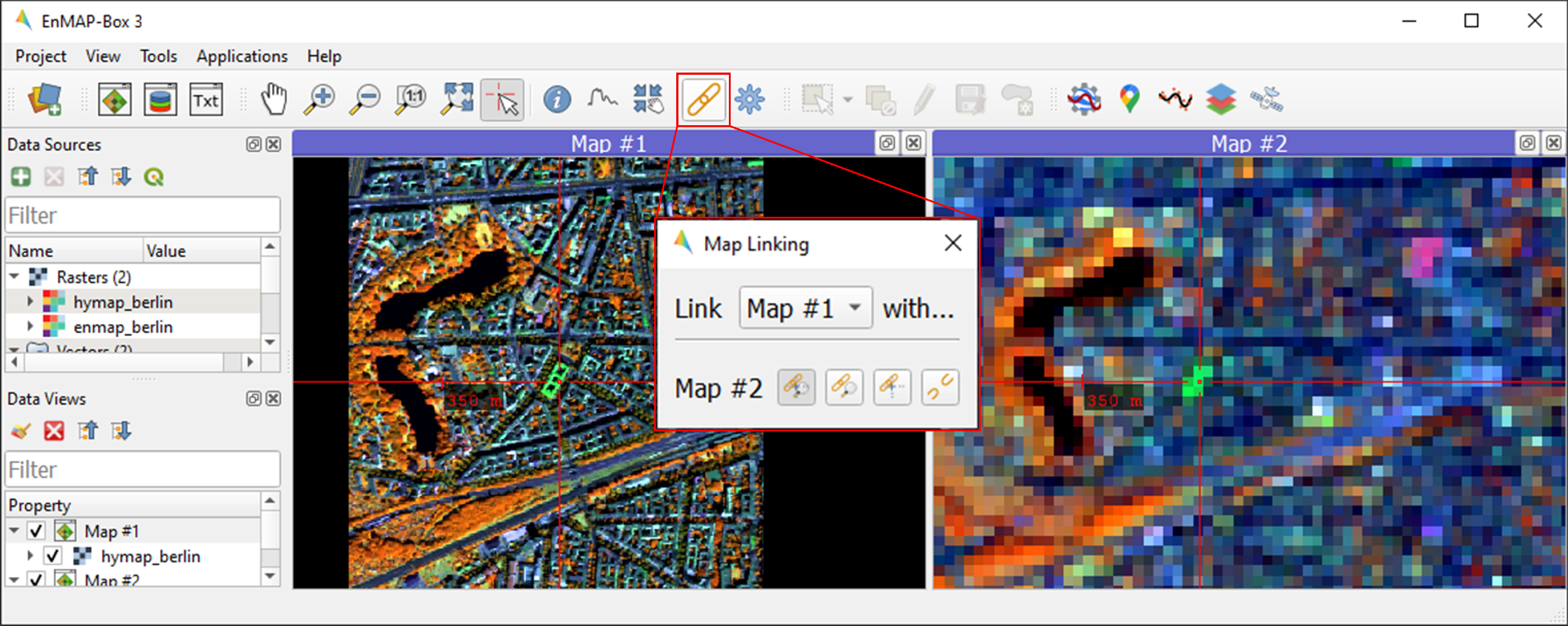
hymap_berlin.tifandenmap_berlin.tifas RGB composite of your preference in Map #1 and Map #2, respectively.To establish geospatial linking, click the
 icon to open the Map Linking window. Choose the
icon to open the Map Linking window. Choose the  Link Map Scale and Center option, and close the dialog.
Link Map Scale and Center option, and close the dialog.
1.3.2. 2. Visualize image spectra
The EnMAP-Box provides Spectral Library Windows (SpectralLibrary #) for visualizing spectra and managing their metadata. To visualize image spectra, activate the Identify tool along with the Identify raster profiles
 option.
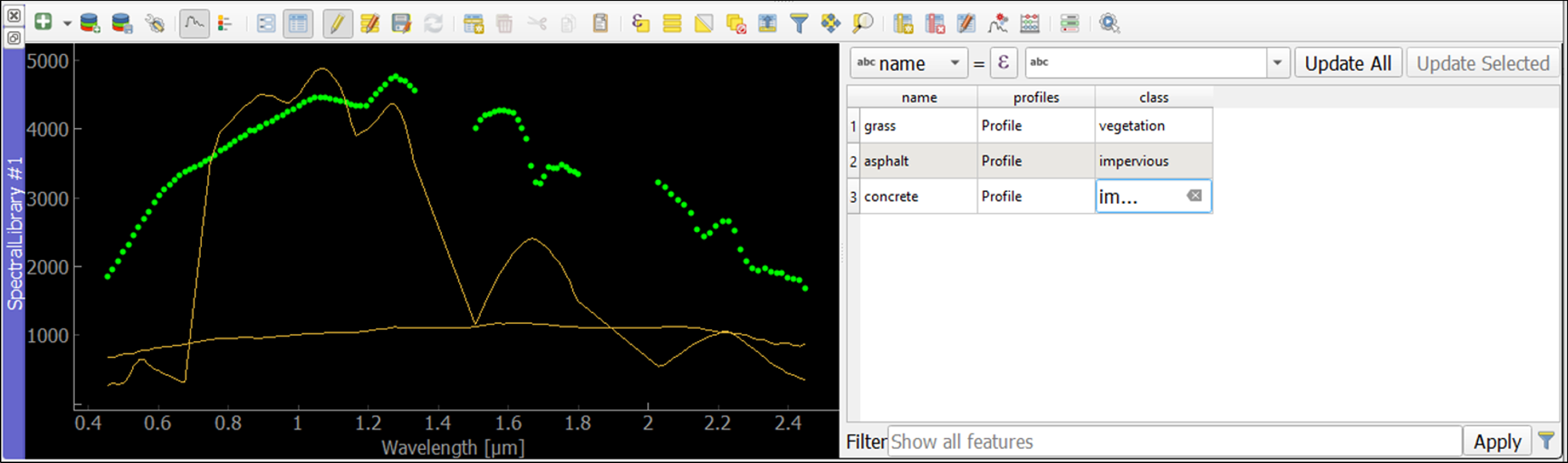
option.Click on an image pixel, and SpectralLibrary #1 will automatically open, displaying the corresponding pixel spectrum (dotted line). The Spectral Profile Sources panel will also open automatically. Note that the plotted spectrum always corresponds to the top-most raster layer of the respective Map Window you click on, unless you change this in the Spectral Profile Sources panel .
Familiarize yourself with the following tools in the Spectral Library #1 toolbar:
The
 icon adds a plotted spectrum to a collection.
icon adds a plotted spectrum to a collection.The
 icon shows the attribute table, which lists every collected spectrum in a separate row.
icon shows the attribute table, which lists every collected spectrum in a separate row.The
 icon can be used to switch on/off the editing mode. If switched on, you can edit the attribute table, add or delete columns using the
icon can be used to switch on/off the editing mode. If switched on, you can edit the attribute table, add or delete columns using the 
 icons, etc.
icons, etc.You can delete selected spectra in editing mode using the
 icon (hold Ctrl or Shift to select multiple rows).
icon (hold Ctrl or Shift to select multiple rows).The
 icon saves a spectrum or a collection of spectra as a spectral library.
icon saves a spectrum or a collection of spectra as a spectral library.
Learning activities
B1: Visually compare the airborne and spaceborne hyperspectral images (
hymap_berlin.tif,enmap_berlin.tif). How much of the spatial detail is lost when stepping from airborne to spaceborne scale?click to expand...
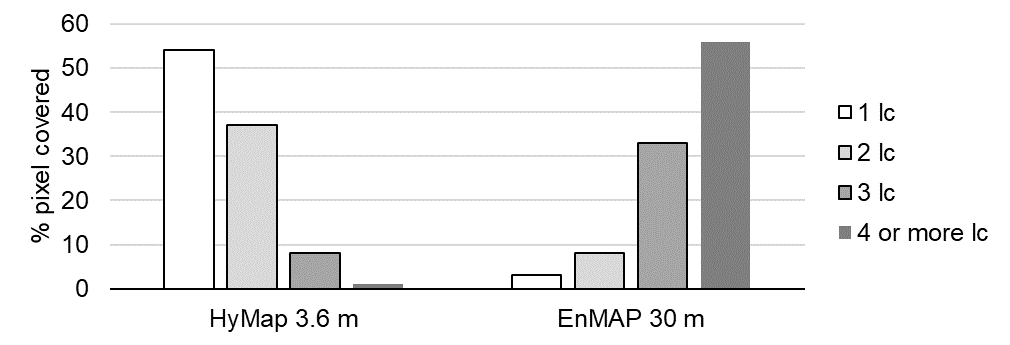
The spatial detail of most urban features (e.g., buildings, streets, trees along streets or in private gardens) disappears due to spatial aggregation at spaceborne scale. However, large homogenous urban features (e.g., waterbodies, sport grounds, tree stand in parks) remain apparent.
B2: Provide an average estimate on the percentage of pixels covered by 1, 2, 3, and 4 or more land cover classes for both images. Use level 3 of the classification scheme for your estimate. You may use the reference land cover information (
landcover_berlin.gpkg) for orientation.click to expand...
B3: Compare pairs of spectra from the airborne and spaceborne hyperspectral images (
hymap_berlin.tif,enmap_berlin.tif). For which urban surface materials is it still possible to collect pure spectra at spaceborne scale, and for which not?click to expand...
Pure spectra can be collected for homogenous urban surfaces with a patch size of ~100 x 100 m and larger (e.g., roofing material spectra for large industrial buildings, ground paving material spectra for yards of industrial complexes, grass spectra on lawns or soccer fields, tree spectra in dense stands, water spectra from water bodies). Pure spectra cannot be collected for urban surfaces with a patch size below ~100 x 100 m (i.e., for most roofing materials, street asphalt, street trees).
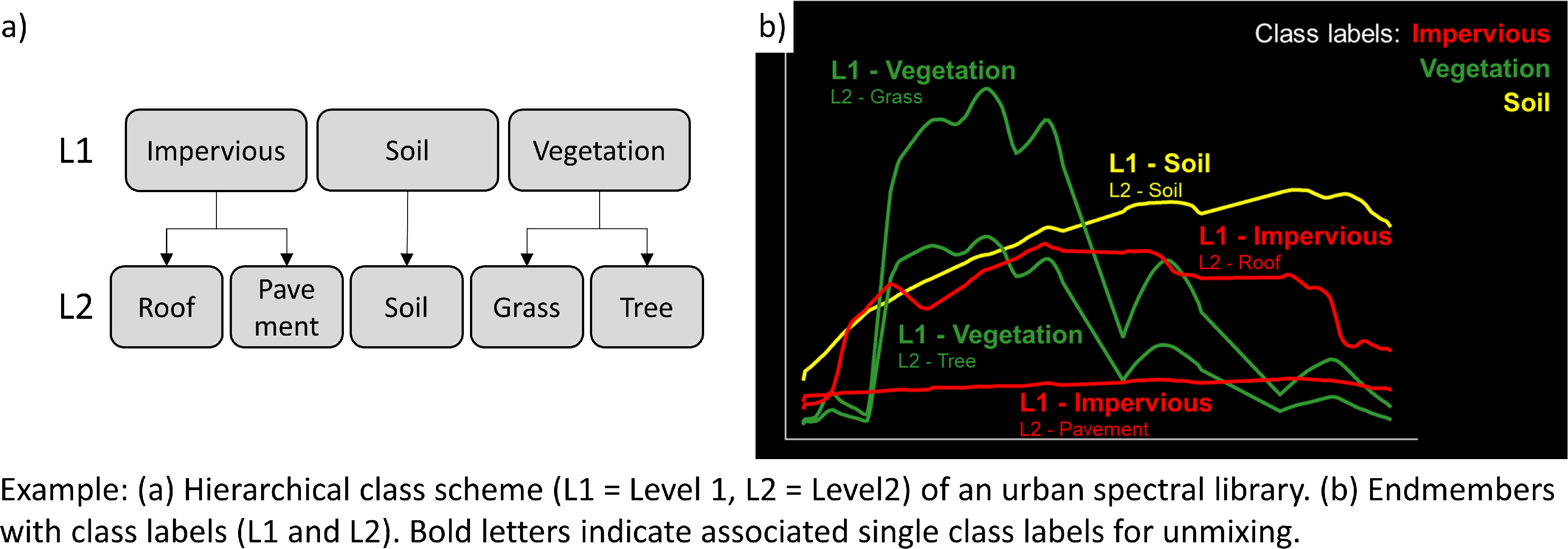
1.4. Exercise C: Urban spectral libraries
Description
Urban spectral libraries comprise collections of pure surface spectra (endmembers) that depict the spectral diversity and variability of urban land cover types at high spectral resolution. These library spectra are commonly derived from laboratory, field, or image data and are well-suited for library-based mapping approaches, such as unmixing. This exercise…
Provides insight into the design of urban spectral libraries and illustrates challenges related to within-class variability and between-class similarity during urban mapping
Focuses on the management of spectral libraries in the EnMAP-Box. You will become familiar with the spectral library format used in the EnMAP-Box and learn how to load and visualize external urban spectral libraries along with their associated.
Duration: 15 min
1.4.1. 1. Load spectral libraries
Close all Map and Spectral Library Windows from the previous exercise.
The Geopackage format
gpkgallows for the effective storage of spectral profiles along with their attributes (e.g., labels, location, descriptions, etc.), thus extending standard spectral library formats like the ENVI Spectral Library.To load the urban spectral library, right-click on
library_berlin.gpkgin the Data Views panel and select Open Spectral Library Viewer.Familiarize yourself with the representation of the spectral library and the attribute table.
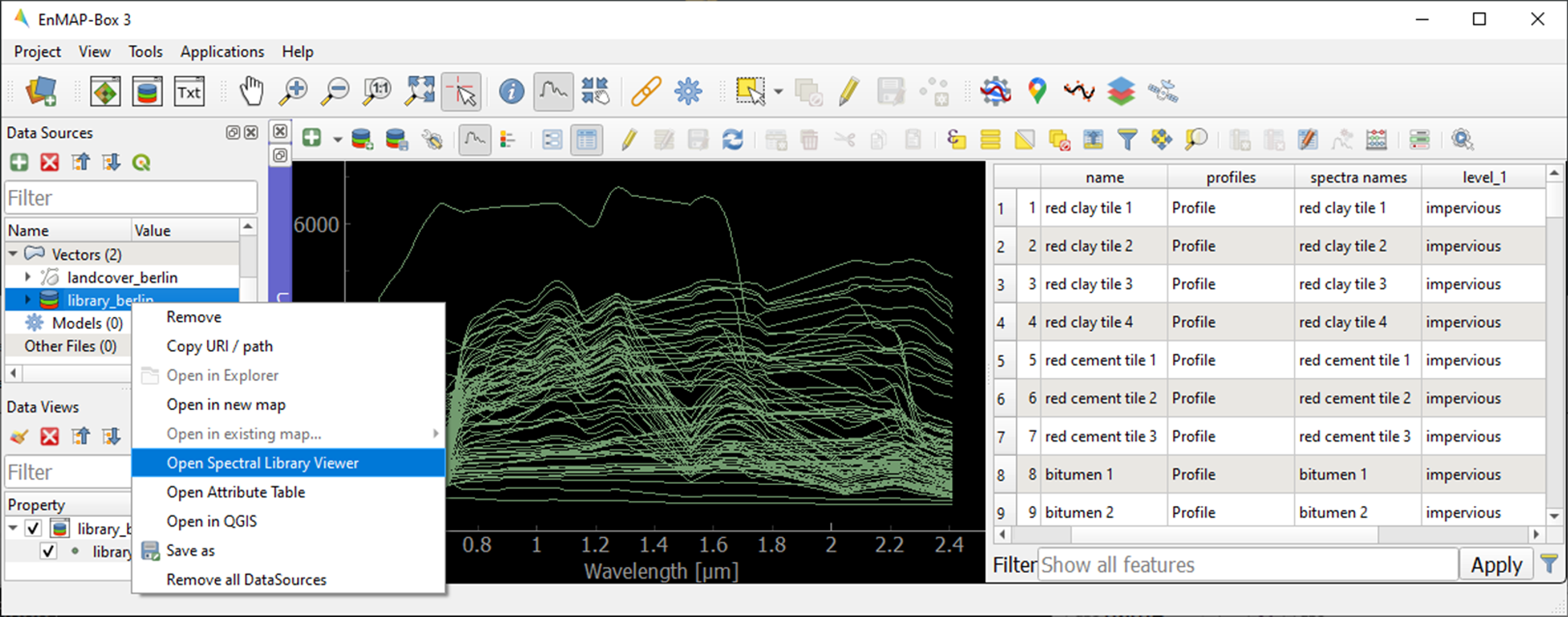
1.4.2. 2. Spectral library handling
You can change the symbology of the displayed spectra using standard QGIS functionality.
Right-click on the spectral library in the Data Views panel, select Layer Properties and navigate to Symbology.
Select Categorized and use the Value and Classify options to change the color representation of the spectral profiles.
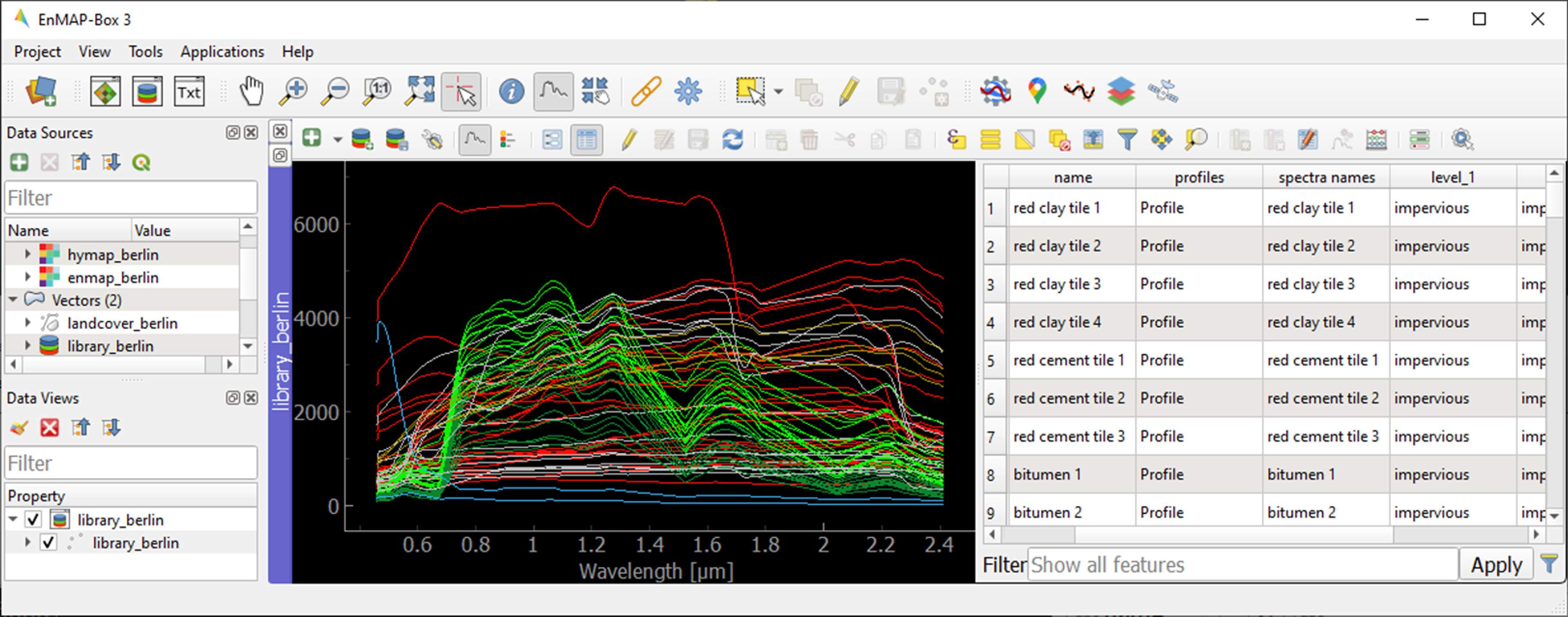
To display a subset of spectra in a separate Spectral Library Window…
Select the spectra of interest by clicking on their corresponding row numbers (use Ctrl or Shift to select multiple rows). To select spectra with the same attributes, prior sorting of the attribute table by clicking on the corresponding column header is recommended.
Click on the
 icon in the toolbar (or Ctrl+C) to copy the selected spectra to clipboard.
icon in the toolbar (or Ctrl+C) to copy the selected spectra to clipboard.Open a second Spectra Library Window. Similar to the work with multiple Map Windows, Spectral Library Windows can be arranged according to the user needs.
Switch on the editing mode
in the SpectralLibrary #2 toolbar and use the  icon (or Ctrl+V) to paste the copied spectra into SpectralLibrary #2. Switch off the editing mode.
icon (or Ctrl+V) to paste the copied spectra into SpectralLibrary #2. Switch off the editing mode.
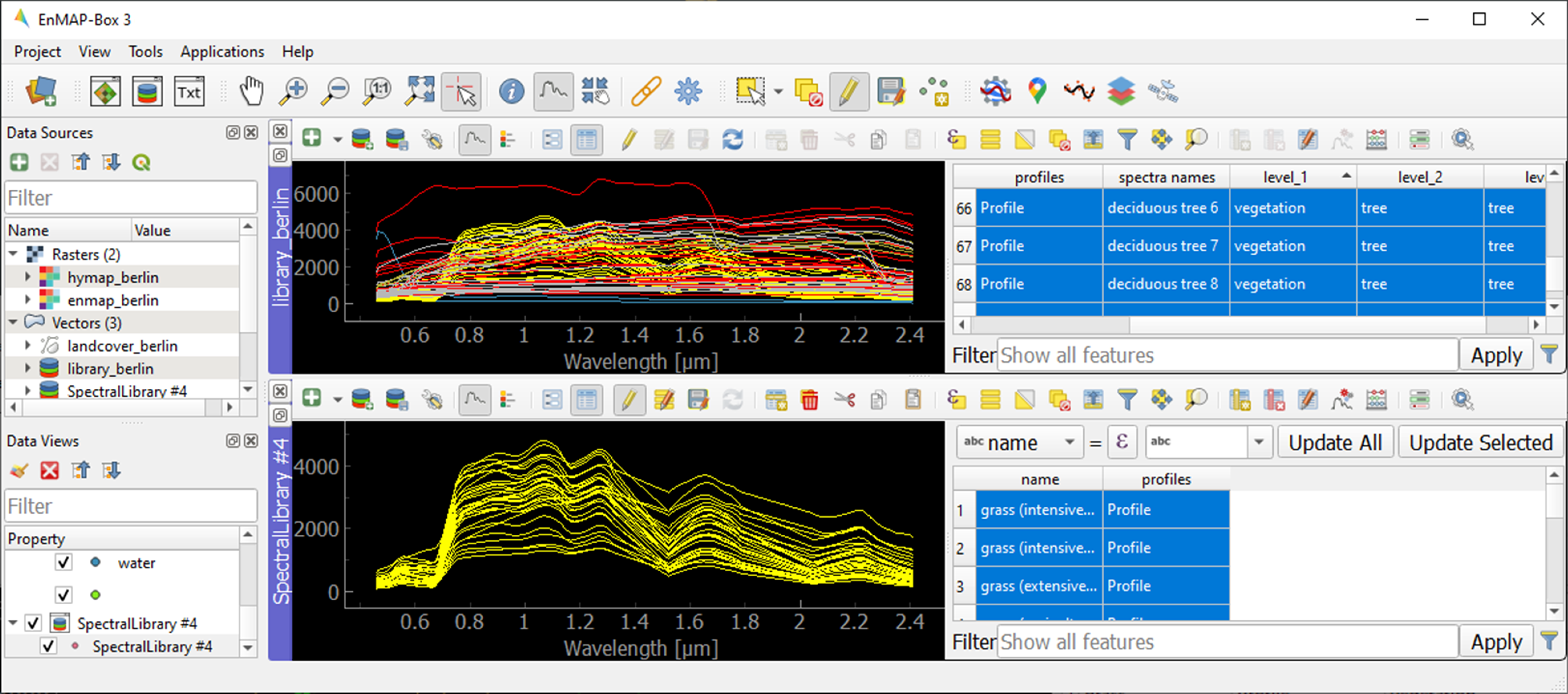
Learning activities
C1: Load the urban spectral library (
library_berlin.gpkg) and display each level 3 class in a separate Spectral Library Window. How diverse is each class with regard to within-class variability?click to expand...
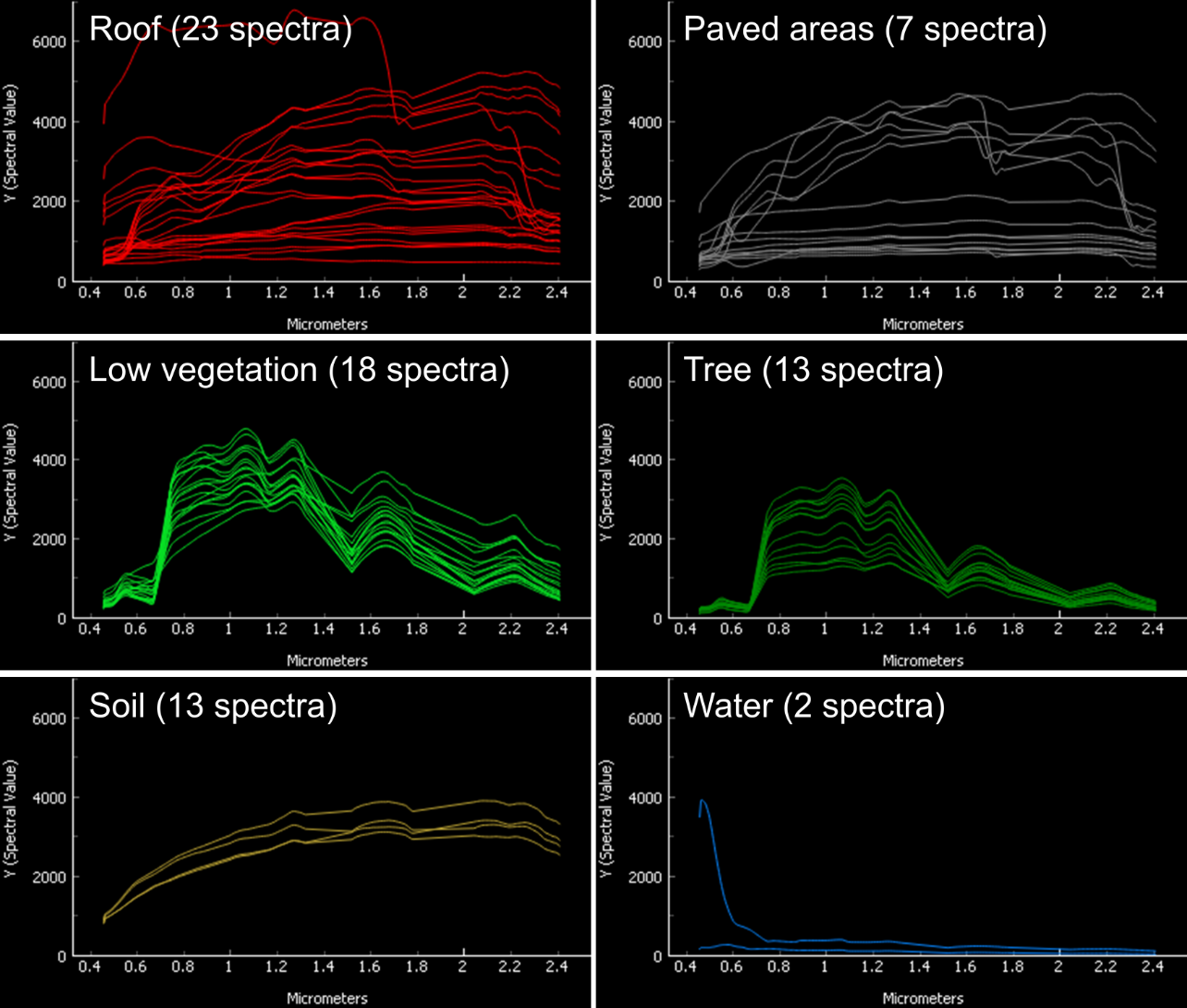
The roof class shows a very high within-class variability. The classes pavement, low vegetation, and tree show a high within-class variability. The classes soil and water show a rather low within-class variability.
C2: List classes which show a high between-class similarity and provide an explanation.
click to expand...
The classes roof and pavement are highly similar with regard to the following surface materials: bitumen vs. asphalt, red clay tiles vs. red sand, grey roofing materials (most likely concrete) vs concrete. The classes roof and soil are highly similar with regard to the following surface materials: concrete vs. bare soil, red clay tiles vs. bare soil. The classes low vegetation and tree are highly similar regarding the following vegetation types: darker grass types (clover, agricultural grassland) vs. brighter trees.
1.5. Exercise D: Regression-based unmixing
Description
To map the land cover composition of urban areas using data from spaceborne imaging spectrometer missions, unmixing proves more useful than discrete classification. This exercise…
Introduces a regression-based unmixing approach for land cover fraction mapping. The approach effectively addresses spectral diversity, variability, and mixing, utilizing synthetic mixtures from spectral libraries to train regression models.
Guides you through using the ‘Regression-based unmixing’ application in the EnMAP-Box.
Duration: 30 min
1.5.1. 1. Introduction
Regression-based unmixing using synthetically mixed data from spectral libraries for land cover fraction mapping is implemented as the Regression-based unmixing application in the EnMAP-Box 3. Given that the implemented regression algorithms are designed for single-output tasks, the procedure is successively conducted internally for each class. In this process, the current class is designated as the target class, while all others are considered as background classes. The workflow of the unmixing approach is illustrated below:
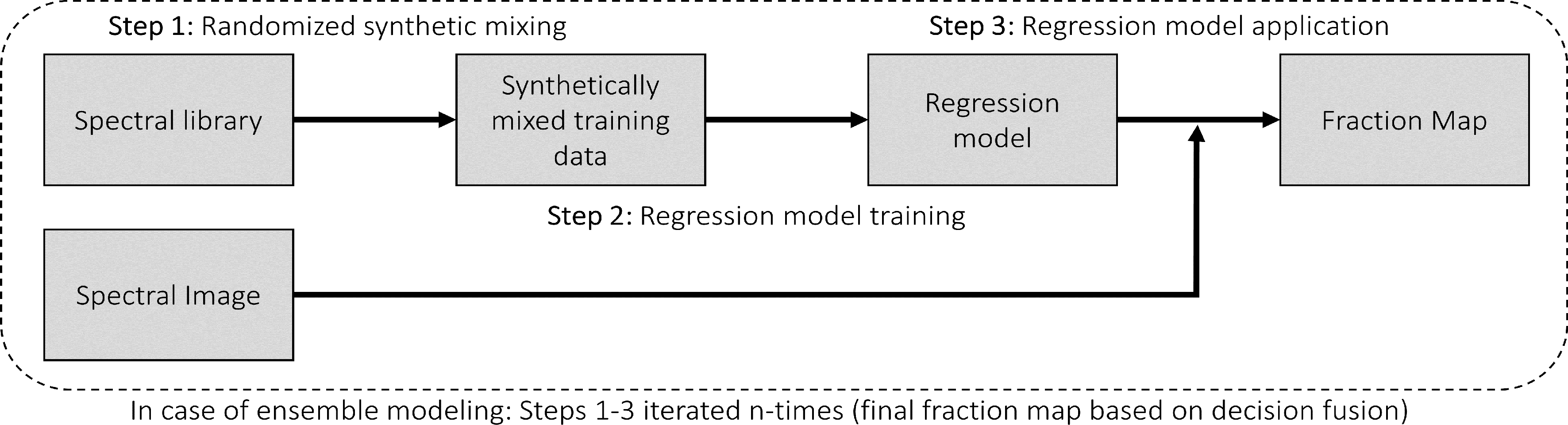
Step 1: An spectral library with associated class information is used to randomly create a synthetically mixed dataset. This involves creating pairs of mixed spectra and associated mixing fractions for each target class.
Step 2: The synthetically mixed dataset is used to train a regression model for each target class.
Step 3: The regression model is applied to an image to derive a fraction map for each target class.
The approach can be integrated into an ensemble framework, where steps 1-3 are iterated n-times and the final fraction map for each target class is created by combining the intermediate maps. The ensemble modeling facilitates the incorporation of diverse synthetic mixtures into the unmixing process, all while maintaining a low training sample size.
1.5.2. 2. Start the application
Close all Map and Spectral Library Windows from the previous exercise.
Load
enmap_berlin.tifas RGB composite of your choice andlibrary_berlin.gpkginto new Map and Spectral Library Windows.Navigate to Applications in the Menu, choose Unmixing, and then Regression-based unmixing.
The Regression-based unmixing GUI will open, consisting of sections for defining Inputs, selecting the Regression algorithm, configuring the Mixing parameters, and specifying the Outputs.
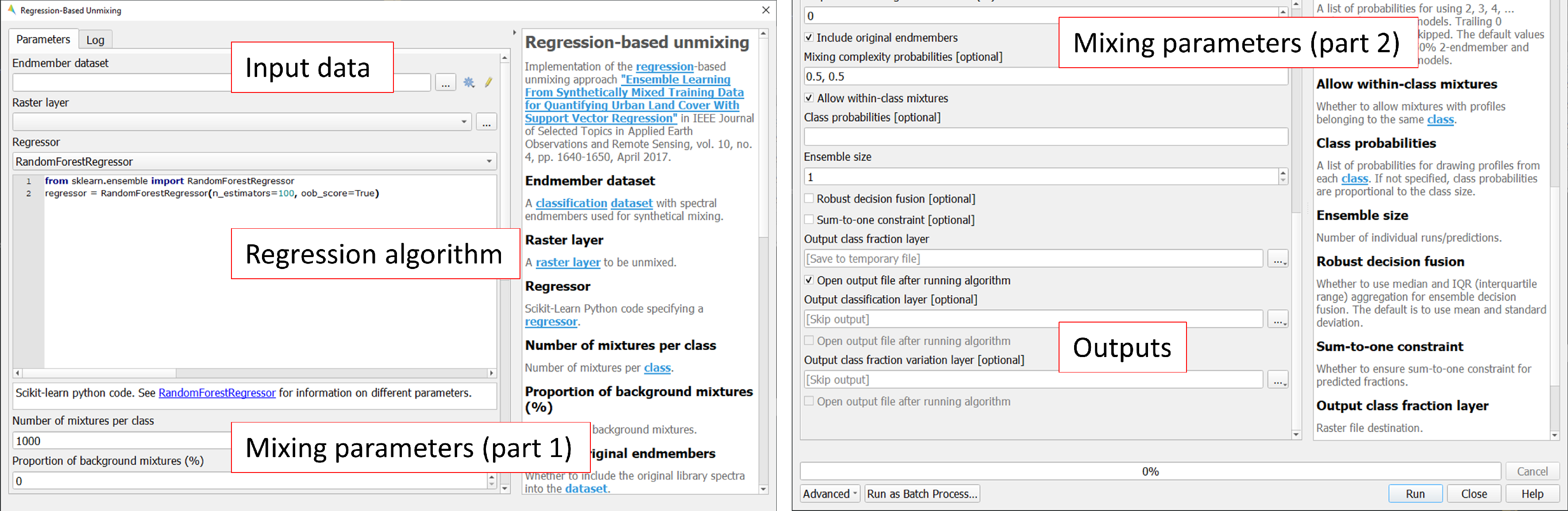
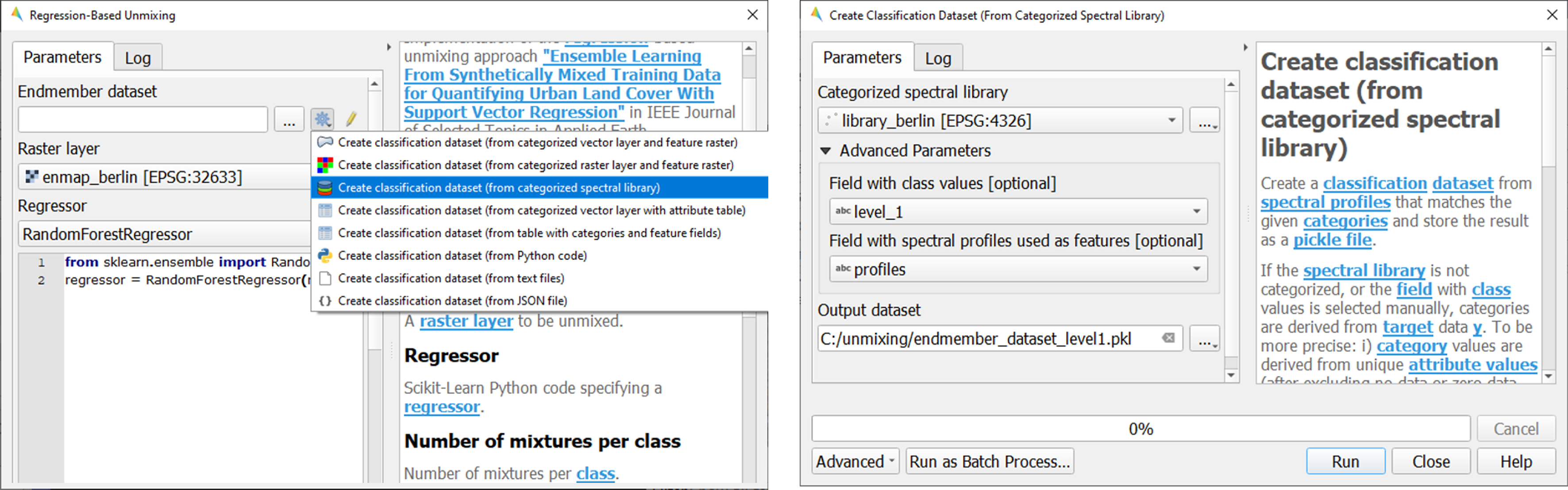
1.5.3. 3. Inputs and class selection
The regression-based unmixing workflow requires two input datasets.
Endmember dataset: Spectral library containing the endmembers with associated class labels (i.e. single or multiple class levels) used for generating synthetic training information for subsequent regression model training. The spectral library has to be converted into a classification dataset wherein each spectral profile is associated with a single class label.
Raster image: An image to which the regression model training will be applied to derive a fraction map.
To set up the Endmember dataset, click on the
 icon and select
icon and select  Create classification dataset (from categorized spectral library). The Create Classification Dataset algorithm will open, where you can specify the following settings:
Create classification dataset (from categorized spectral library). The Create Classification Dataset algorithm will open, where you can specify the following settings:Categorized spectral library:
library_berlin.gpkgField with class values: level_1
Field with spectral profiles: profiles
Output dataset: Path/filename to store the classification dataset
Execute the process. The classification dataset will be visible in the Data Source panel and automatically assigned as the Endmember dataset.
1.5.4. 4. Regression Algorithm
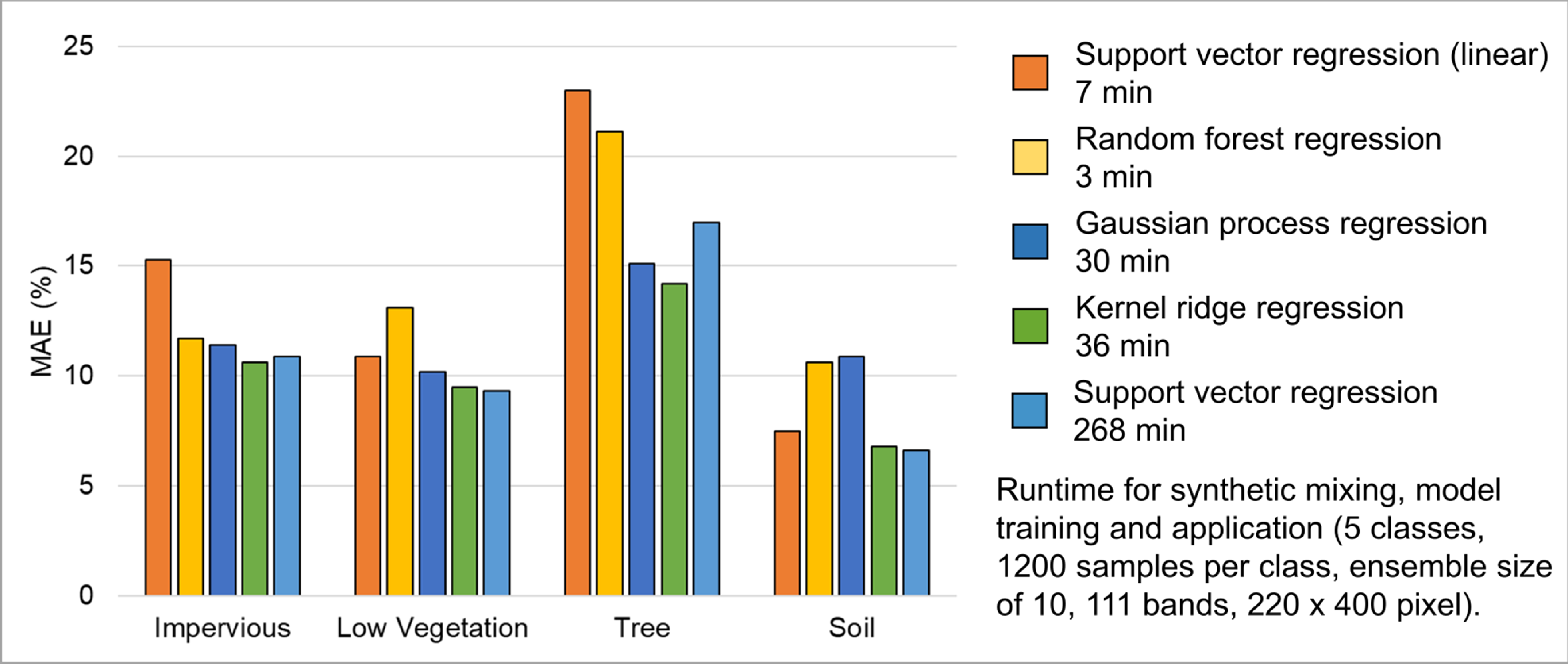
The subsequent step involves selecting a regression algorithm. The EnMAP-Box provides a range of state-of-the-art algorithms from the scikit-learn library (see https://scikit-learn.org/stable/index.html). It’s important to note that different algorithms may result in varying accuracies and processing times, especially when incorporating the unmixing process into an ensemble.
Choose RandomForestRegression from the dropdown menu as the Regressor due to its lower processing time. Keep the default parameter settings. Refer to the scikit-learn documentation for more information.
Iterate the unmixing 3 times by setting Ensemble size to 3 (scroll down).
1.5.5. 5. Mixing parameters
The mixing parameters steer the process of generating the synthetically mixed training data from the spectral library.
The Number of mixtures per class specifies the total number of synthetic mixtures per target class to be created.
The Proportion of background mixtures enables the user to increase the number mixtures, i.e. mixtures between endmembers that do not belong to the current target class.
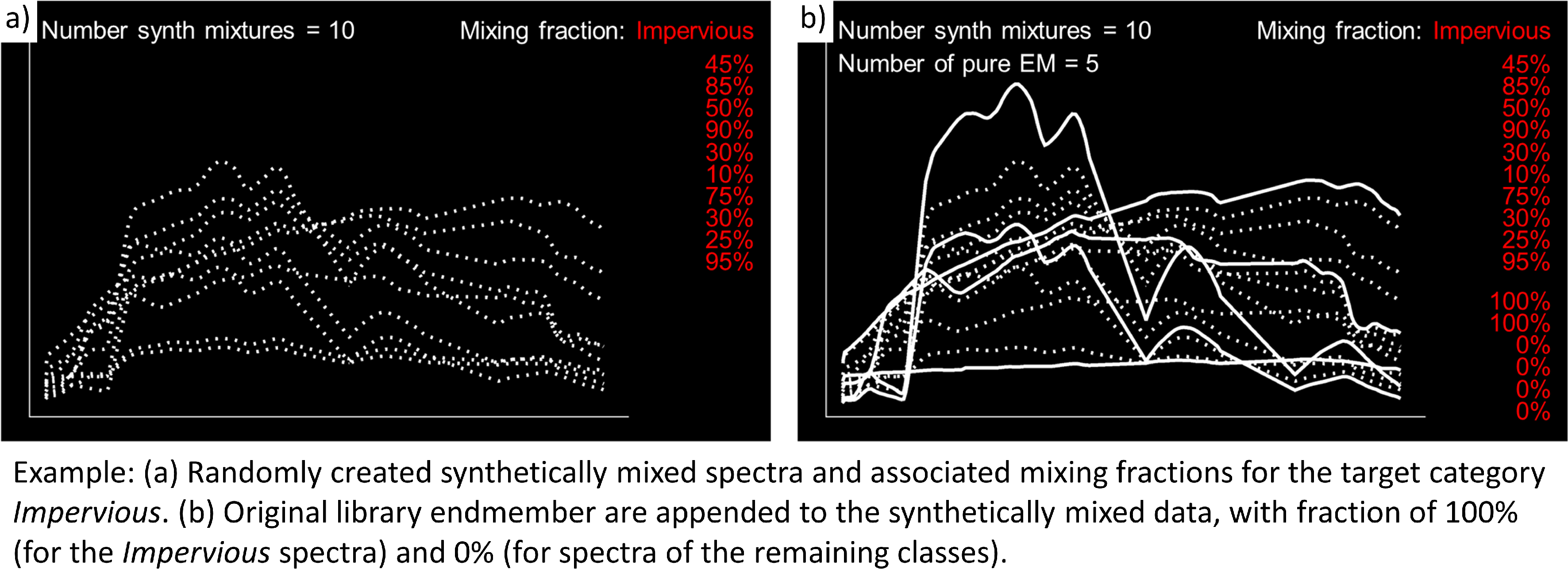
The check option to
 Include original endmembers allows to append the spectral library to the synthetically mixed training data, with fractions of either 0% or 100% of a respective target class.
Include original endmembers allows to append the spectral library to the synthetically mixed training data, with fractions of either 0% or 100% of a respective target class.
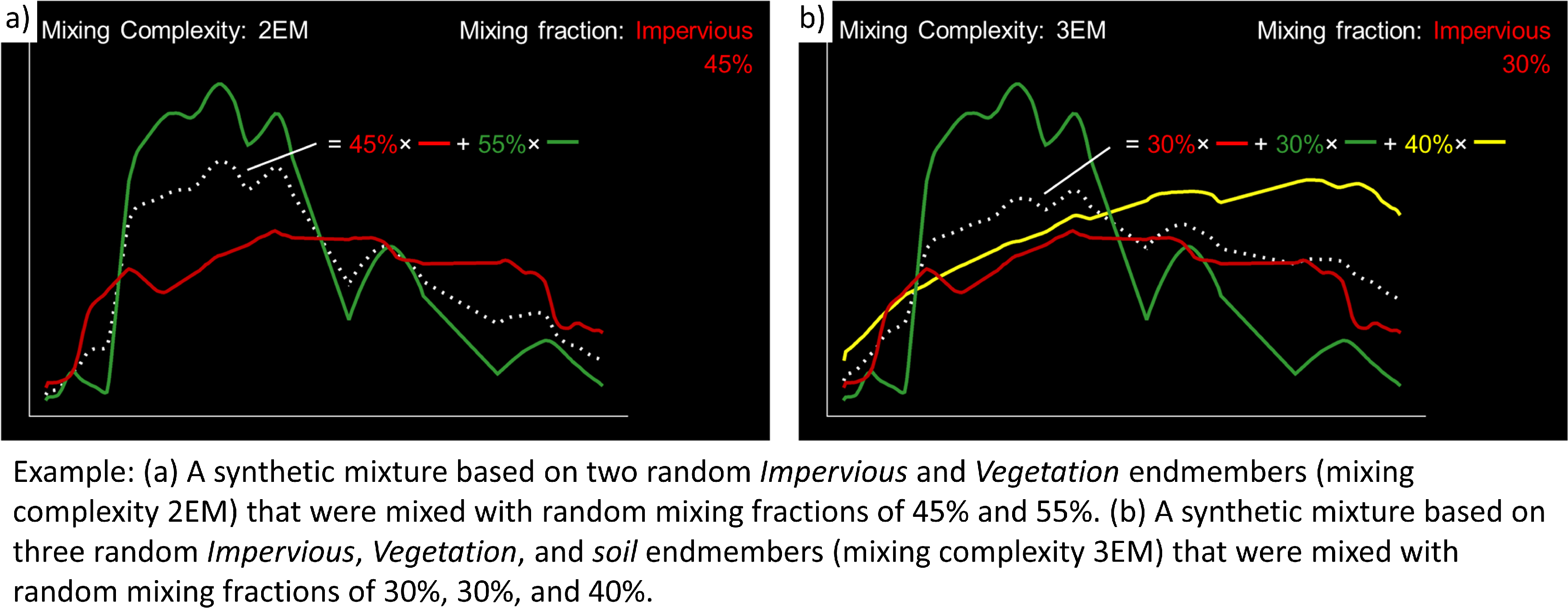
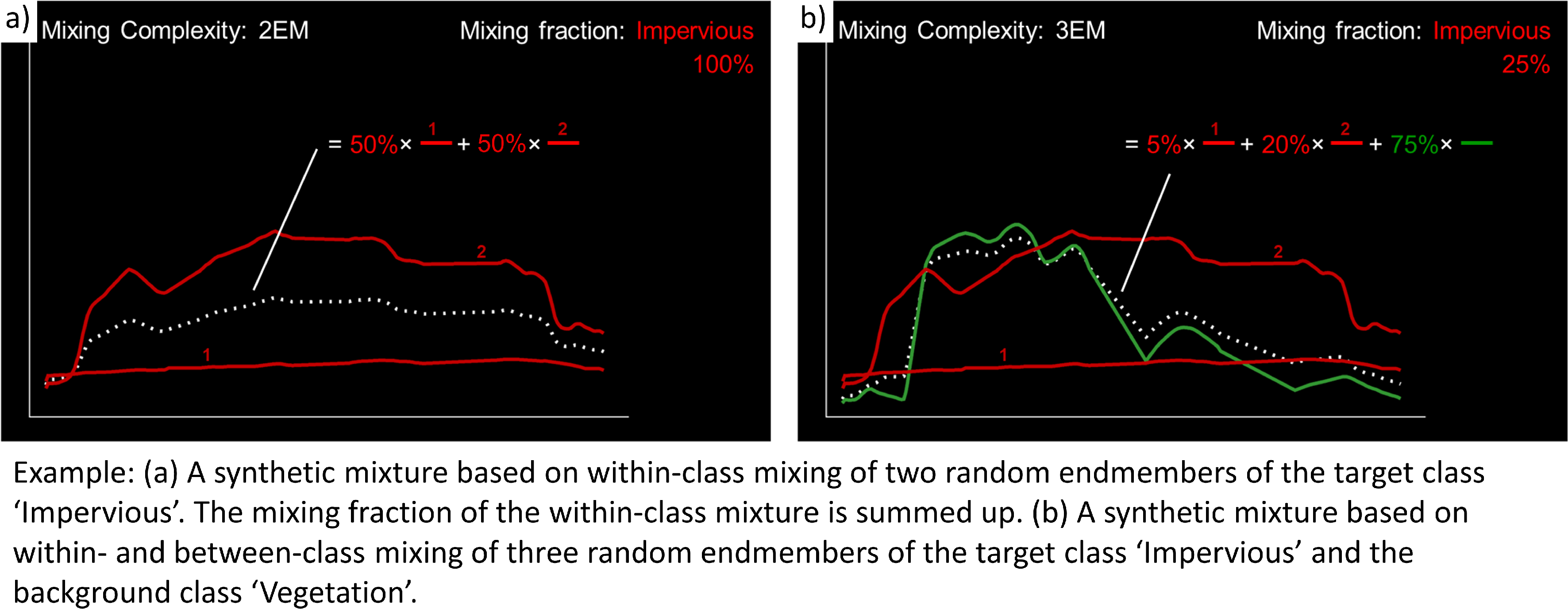
The synthetic mixing process itself is randomized. That is, to generate a synthetic mixture …
… a mixing complexity is randomly assigned, determining the number of endmembers contributing to a mixture (e.g., 2EM, 3EM). User-defined :guilabel: ‘Mixing complexity probabilities’ guide this random selection; for instance, 0.6 and 0.4 imply a 60% chance of a two-endmember mixture and a 40% chance of a three-endmember mixture. Ensure that the probabilities sum up to 1.
… endmembers are randomly sampled from the library. The number of endmembers is determined by the previously assigned mixing complexity. The first endmember is always drawn from the target class. Subsequent endmembers are sampled based on Class probabilities, which are either proportional to the class size (default; if not specified) or can be defined by the user. The
Allow within-class mixtures check option enables the user to decide whether multiple endmembers of the same class can be sampled to create a mixture.… mixing fractions between 0 and 1 (0-100%) are randomly assigned to the previously drawn endmembers. The total sum of fractions is always 1 (100%).
… endmembers are linearly combined based on the mixing fractions to create the mixture.
Select the following mixing parameters:
Number of synthetic mixtures per class:
1000(default)Include original endmembers: Yes (default)
Mixing complexity probabilities: 2EM=
0.4, 3EM=0.4, 4EM=0.2Allow within-class mixtures: Yes (default)
Class probabilities: Proportional (leave unspecified = default)
1.5.6. 6. Outputs
The final component of the regression-based unmixing application involves specifying the outputs.
Output class fraction layer: Path/filename to store the final fraction maps of the target classes.
Output classification layer: Optional output to store a discrete classification map derived from the final fraction map, where each pixel is assigned the class with the maximum class fraction.
Output class fraction variation layer: Optional output to store the variation of the intermediate fraction maps from ensemble modeling.
Two additional options enable the user to modify the output fraction map.
Robust decision fusion: Option to determine the method of combining intermediate fraction maps from ensemble modeling. The default setting involves utilizing the mean and standard deviation. By selecting this option, the combination is based on the median and interquartile range.
Sum-to-one constraint: Option for post-hoc normalization of fractions to ensure they sum to one. This involves dividing the fractions of each class by the total sum of fractions across all classes.
Specify the following outputs:
Output class fraction layer: Path/filename to store the
class fraction layer_prediction.tif
1.5.7. 7. Run the application
Execute the process. The outputs will be visible in the Data Source panel.
1.5.8. 8. Visualize the urban land cover fraction map
The
class fraction layer_prediction.tifconsists of 4 bands, where each band represents a fraction map of a respective target class. Display map in a useful render style and appropriate contrast stretch:e.g., as multiband RGB composite of three target classes in a single Map Window. For stretching fraction maps to the full range of possible fraction, set Min = 0 and Max = 1.
e.g., as singleband greyscale image per target class in multiple Map Windows. For stretching fraction maps to the full range of possible fraction, set Min = 0 and Max = 1.
Visually explore your fraction map. Display
enmap_berlin.tifin a separate Map Window for comparison. You may use the Identify tool together with the Identify cursor location values option to display fraction values of pixels.
option to display fraction values of pixels.
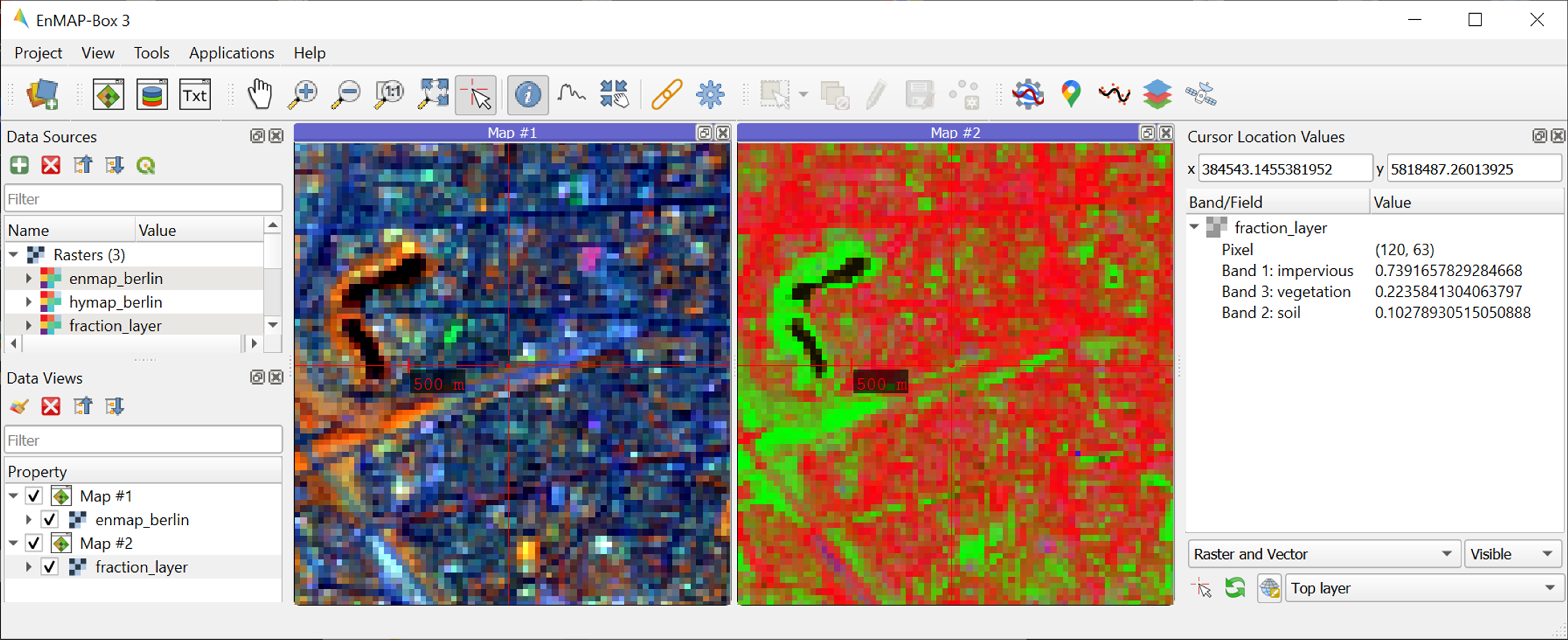
Learning activities
D1: Visually explore the fraction map (
class fraction layer_prediction.tif). How are level 1 land cover distributed across the urban gradient. Are the fraction values physically plausible?click to expand...
High impervious fractions can be observed in the city center. A general increase in vegetation cover and decrease in impervious cover is observed when moving towards suburban areas. Soil is only abundant on single patches, e.g., along rail tracks or on construction sites. Fractions for each class are in the physically meaningful range between 0 and 1. The sum of fractions per pixel over all classes is, however, often larger than 1.
D2: Do you observe an over- or underestimation of fractions for specific land cover types indicating errors in map?
click to expand...
Soil fractions are overestimated by around 20%, particularly for areas where red clay tiles / bitumen / asphalt mixtures are apparent but no soil surfaces. Water fractions are overestimated by around 20% throughout the city on all impervious surfaces.
1.6. Exercise E: Validation of fraction maps
Description
Validation of fraction maps is typically performed by comparing estimated and reference fractions through scatterplots and various statistical measures. These measures include mean absolute error, root mean squared error, R², as well as the slope and intercept of a linear fitted regression model. This exercise……
Illustrates the validation procedure for fraction maps.
Introduces EnMAP-Box geoalgorithms for producing reference fractions from high resolution land cover information and statistical accuracy assessment of fraction maps.
Duration: 15 min
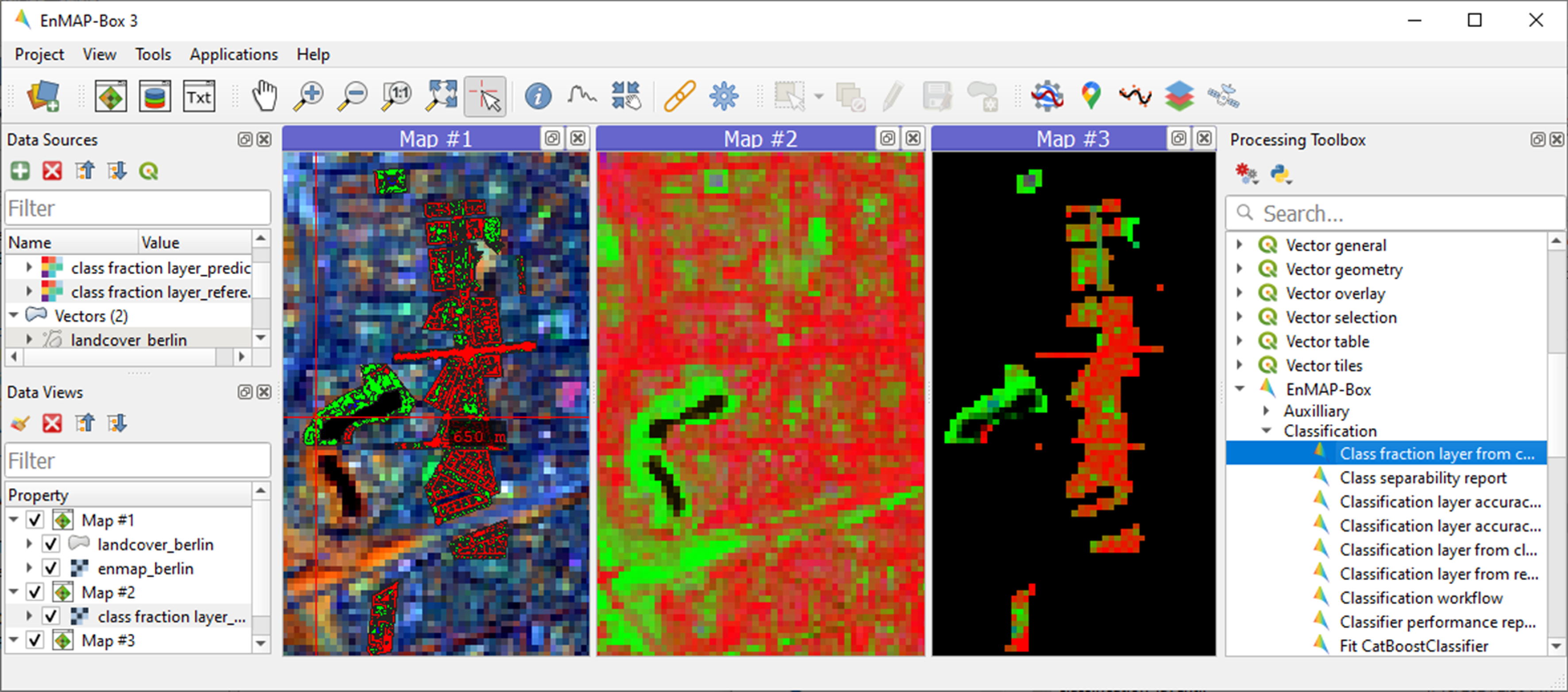
1.6.1. 1. Create reference fraction map
The generation of a reference fraction map involves converting the existing reference land cover information into the pixel grid of the estimated fraction map through rasterization. Achieving accurate fractions requires the reference land cover information to be at a notably higher spatial resolution than the pixel grid.
Close all Map and Spectral Library Windows from the previous exercise.
Load
enmap_berlin.tifas an RGB composite of your choice into new Map Window.Load
landcover_berlin.gpkginto the same Map Window visualize the land cover based on the level 1 scheme.Click on the
 icon in the menu to open the QGIS Processing Toolbox, where you can find the EnMAP-Box geoalgorithms.
icon in the menu to open the QGIS Processing Toolbox, where you can find the EnMAP-Box geoalgorithms.Run the algorithm with the following settings:
Categorized vector layer:
berlin_landcover.gpkgGrid:
enmap_berlin.tifMinimal pixel coverage [%]: 0.95
Output class fraction layer: Path/filename to store the
class fraction layer_reference.tifExecute the process. The result will be visible in the Data Source panel.
Display
class fraction layer_prediction.tifandclass fraction layer_reference.tifas multiband RGB composites (e.g. R=impervious, G=vegetation, B=soil, min=0, max=1) in two additional Map Windows.
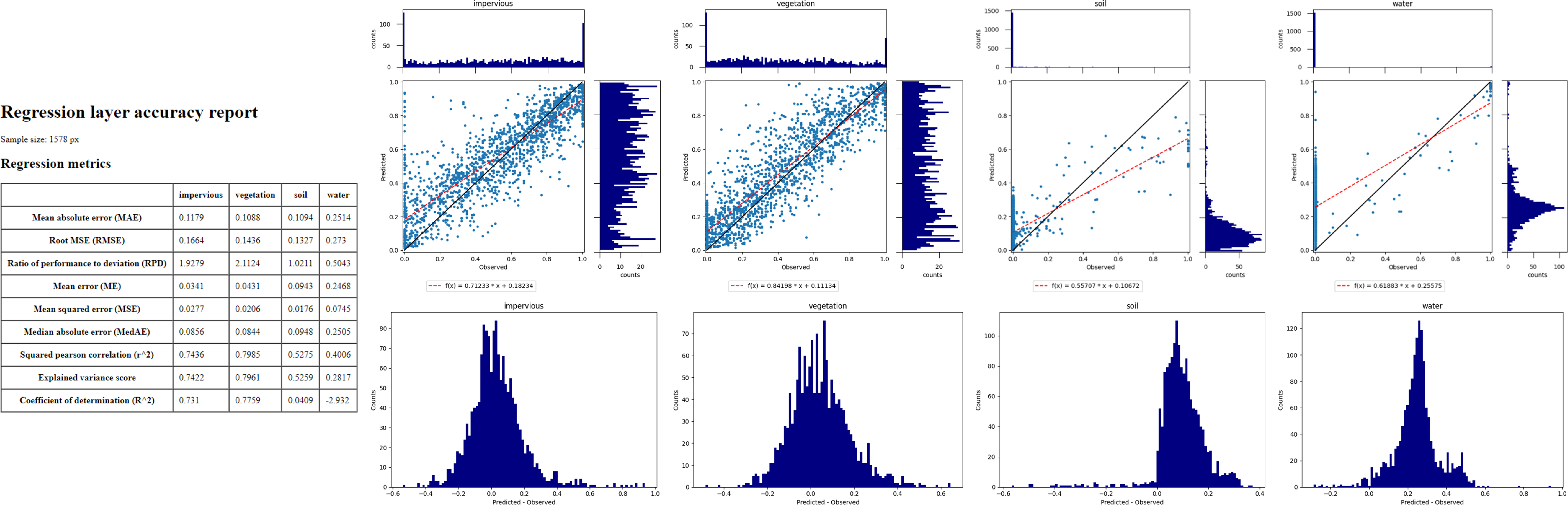
1.6.2. 2. Statistical validation of fraction maps
Validation is conducted by comparing prediction and reference fractions.
Run the algorithm to conduct the validation with the following settings:
Regression layer:
class fraction layer_prediction.tifObserved continuous-valued layer:
class fraction layer_reference.tif
Execute the process, and the results will open in your default explorer.
Make yourself familiar with the HTML report.
Learning activities
E1: Visually compare your estimated fraction map (
class fraction layer_prediction.tif) with the reference fraction map (class fraction layer_reference.tif). Do both maps show a good agreement in terms of spatial patterns or are there areas with large differences?E2: Discuss the accuracy of your fraction map. What are the accuracies for the different classes and which classes show striking errors like underestimation or overestimations of fractions?
1.7. Additional Exercises
Additional learning activities
AE1: Repeat Exercises D & E using the two other class schemes (level 2, level 3) stored in the spectral library metadata and the land cover reference information. How do the accuracies vary and where are the limitations in mapping the more detailed class levels?
AE2: Explore the effects of changing the mixing parameters on the mapping accuracy of the level 2 classes. For more direct comparison, we recommend to alter only one parameter at a time. We further recommend to use the Random Forest Regression due to the low processing time. For example, …
change the Number of synthetic mixtures per class: e.g. 10 vs. 1000 vs. 2000
do not Include original endmembers
change the Mixing complexity probabilities: e.g. only 2EM vs. only 3EM vs. only 4EM
change the Ensemble size: e.g. 1 vs. 10 vs. 20
AE3: Compare the performance of the different regression algorithms offered in the EnMAP-Box. Please note that the other regressors have significantly longer processing times.