Fit KMeans
K-Means clustering.
K-means clustering is an unsupervised machine learning algorithm used for partitioning a dataset into distinct, non-overlapping groups or clusters.K-means clustering aims to minimize the within-cluster variance or sum of squared distances from data points to their assigned cluster centroids.
Usage:
Open the algorithm from the processing toolbox.
Load an existing training dataset or create one by clicking the processing algorithm icon, then click run.
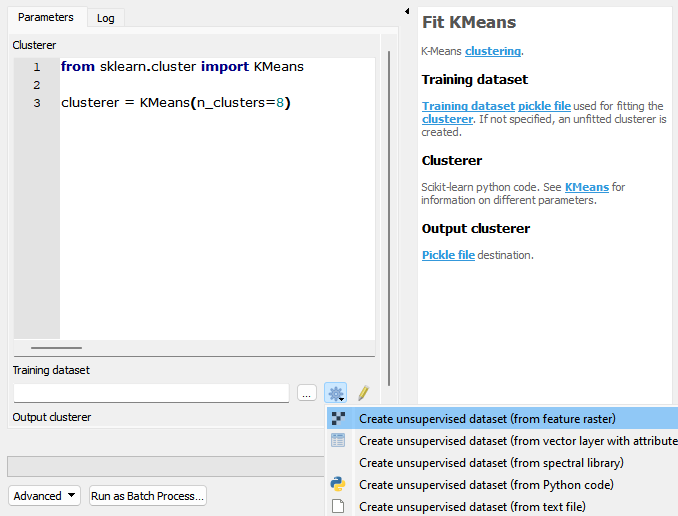
Parameters
- Clusterer [string]
Scikit-learn python code. See KMeans for information on different parameters. Default:
from sklearn.cluster import KMeans clusterer = KMeans\(n_clusters=8, n_init=10\)
- Training dataset [file]
Training dataset pickle file used for fitting the clusterer. If not specified, an unfitted clusterer is created.
Outputs
- Output clusterer [fileDestination]
Pickle file destination.
Command-line usage
>qgis_process help enmapbox:fitkmeans:
----------------
Arguments
----------------
clusterer: Clusterer
Default value: from sklearn.cluster import KMeans
clusterer = KMeans(n_clusters=8, n_init=10)
Argument type: string
Acceptable values:
- String value
- field:FIELD_NAME to use a data defined value taken from the FIELD_NAME field
- expression:SOME EXPRESSION to use a data defined value calculated using a custom QGIS expression
dataset: Training dataset
Argument type: file
Acceptable values:
- Path to a file
outputClusterer: Output clusterer
Argument type: fileDestination
Acceptable values:
- Path for new file
----------------
Outputs
----------------
outputClusterer: <outputFile>
Output clusterer